728x90
DataFrame.duplicated(subset=None, keep='first')
option
- subset : 중복을 확인할 column 리스트
- keep : ['first','last',False] 중 선택
keep='first' 인 경우, 중복 행 중 첫 행만 False, 나머지 True
keep='last' 인 경우, 중복 행 중 마지막 행만 False, 나머지 True
keep=False 인 경우, 중복 행 전부 True
모든 옵션에서 중복 없는 행은 False
Example
DataFrame 생성
import pandas as pd
df = pd.DataFrame({'class':['A','A','A','B','B','B'],
'num':[1,2,2,2,1,1],
'price':[20,10,12,30,90,12]})
중복확인 (keep='first')
df.duplicated(subset=['class'], keep='first')중복 행 중 첫 행만 False이고 나머지는 True인 것을 확인할 수 있습니다.


중복확인 (keep='last')
df.duplicated(subset=['class'], keep='last')중복 행 중 마지막 행만 False이고 나머지는 True인 것을 확인할 수 있습니다.

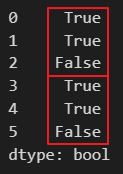
중복확인 (keep=False)
df.duplicated(subset=['class'], keep=False)모든 중복 행이 True인 것을 확인할 수 있습니다.


중복확인 (두 column)
df.duplicated(subset=['class','num'], keep='first')두 column 값이 전부 중복된 행을 찾을 수 있습니다.


'프로그래밍 > Python' 카테고리의 다른 글
| [파이썬, Python] Pandas.DataFrame 행/열 제거 (drop) (0) | 2023.08.01 |
|---|---|
| [파이썬, Python] Pandas.DataFrame 중복 값 제거 (drop_duplicates) (0) | 2023.07.31 |
| [파이썬, Python] 파이썬 파일 확장자 변경 (.ipynb ↔ .py) (0) | 2023.02.17 |
| [파이썬, Python] csv 파일 저장 및 불러오기 (read_csv, to_csv) (0) | 2023.01.23 |
| [파이썬, python] dataframe 정렬 (sort_values) (0) | 2023.01.20 |


